
Hermes 每次会话将 MEMORY.md 以冻结快照方式注入上下文。使用久了 MEMORY.md 积累的条目过多、过散,超过设定的阀值就会被压缩,然后时间长了,记忆太多的情况下,Hermes会掉用模型对记忆信息进行筛选,哪些是值得长期记忆,哪些又是相对不重要在满时可以丢弃的。但这个判断并不一定100%准确,可能错误地用新记忆替换了一些旧记忆,导致旧记忆丢失的情况,也有可能记忆太多只能丢掉一些模型认为相对不重要的记忆。这样你在使用到的时候会发现,我的Hermes貌似失忆了。所以我们要使用第三方记忆系统来长期完整的记录下来,Hermes默认内置的第三方记忆系统有很多,今天就来详细聊聊在 Ubuntu 24.04 LTS 服务器上部署 Hindsight 记忆服务,配置自定义 LLM 端点和外部 PostgreSQL 数据库的踩坑实录。
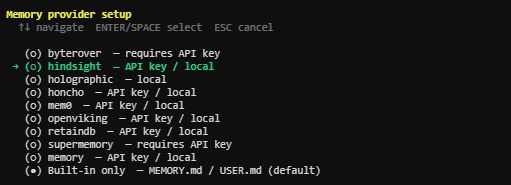
背景
Hindsight 是 Vectorize.io 开源的记忆服务,可以为 AI Agent 提供长期记忆能力。支持:
- 自动记忆提取和存储
- 语义搜索召回
- 与 Hermes Agent 无缝集成
官网: https://vectorize.io/hindsight
Github:https://github.com/vectorize-io/hindsight
- 有官网云端版,官网注册申请一个Key就能用,但数据库上传到云端。
环境要求
- 操作系统: Ubuntu 24.04 LTS
- Docker: v24.0+(需要支持 pgvector)
- 磁盘空间: 至少 15GB(镜像约 6.2GB + 数据库及数据)
- 内存: 建议 4GB+(模型用了外部LLM模型,非本地内嵌模型,所以不需要太大内存和显卡)
一、Docker 环境检查
首先确认 Docker 已安装并运行:
docker --version
# Docker version 27.5.1, build 9a31bce
docker ps
# 确认 Docker daemon 正常运行
二、拉取 Hindsight 镜像
docker pull ghcr.io/vectorize-io/hindsight:latest
镜像约 6.2GB左右,拉取时间取决于网络速度。如果网络慢,可以使用国内中转镜像:
# 中转镜像 将 ghrc.io -> ghcr.nju.edu.cn
docker pull ghcr.nju.edu.cn/vectorize-io/hindsight:latest
# 再把tag改回 `ghcr.io/vectorize-io/hindsight:latest`,不改也没事,后面用的也要改成这个
docker tag ghcr.nju.edu.cn/vectorize-io/hindsight:latest ghcr.io/vectorize-io/hindsight:latest
docker rmi ghcr.nju.edu.cn/vectorize-io/hindsight:latest
三、初始配置与第一个坑
这里使用的是本地自定义模型中转。如果使用内置支持的模型配置更简单只要一个Key就可以了。
| Provider | 环境变量 | 说明 |
|---|---|---|
| OpenAI | OPENAI_API_KEY |
GPT-4o, GPT-4o-mini |
| Anthropic | ANTHROPIC_API_KEY |
Claude 3.5 |
| Gemini | GEMINI_API_KEY |
Gemini 1.5 |
| Groq | GROQ_API_KEY |
Llama, Mixtral |
| Ollama | OLLAMA_BASE_URL |
本地模型 |
| LM Studio | LMSTUDIO_BASE_URL |
本地模型 |
| MiniMax | MINIMAX_API_KEY |
MiniMax MoE |
3.1 启动命令
docker run -d --name hindsight --restart unless-stopped \
-p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_PROVIDER=openai \
-e HINDSIGHT_API_LLM_API_KEY='your-api-key' \
-e HINDSIGHT_API_LLM_BASE_URL='https://llm.zengwu.com.cn/v1' \
-e HINDSIGHT_API_LLM_MODEL='glm-5' \
-e HINDSIGHT_API_EMBEDDINGS_PROVIDER=openai \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_MODEL='bge-m3' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_API_KEY='your-api-key' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_BASE_URL='https://llm.zengwu.com.cn/v1' \
-v ~/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latest
3.2 坑一:LLM 端点协议错误
错误现象:启动时 LLM 连接失败
原因:LLM 端点必须使用 HTTPS,不能是 HTTP
解决方案:
# 错误
HINDSIGHT_API_LLM_BASE_URL='http://llm.zengwu.com.cn/v1'
# 正确
HINDSIGHT_API_LLM_BASE_URL='https://llm.zengwu.com.cn/v1'
四、第二个坑:PostgreSQL 数据目录权限
4.1 错误现象
mkdir: cannot create directory '/home/hindsight/.pg0': Permission denied
4.2 解决方案
容器内 hindsight 进程以 uid=1000 运行,需要确保数据目录权限正确:
# 在宿主机上执行
mkdir -p ~/.hindsight-docker
chmod 777 ~/.hindsight-docker
或者更精确地授权:
chown -R 1000:1000 ~/.hindsight-docker
五、第三个坑:磁盘空间不足
5.1 错误现象
系统是PVE的LXC中安装的Ubuntu24.04,磁盘默认用了8G,Hindsight 启动后占用约 8GB,初始磁盘直接撑满:
Filesystem Size Used Avail Use% Mounted on
/dev/loop6 7.8G 7.8G 0 100% /
5.2 解决方案
如果使用的是 LXC/Proxmox 容器,需要扩展磁盘:
- 在 Proxmox 控制台扩展磁盘(如扩展到 20GB)
- 在容器内扩展文件系统:(LXC不自动扩容了,虚拟机需要以下操作)
# 检查当前磁盘
df -h
# 扩展逻辑卷(如果使用 LVM)
lvextend -l +100%FREE /dev/loop6
resize2fs /dev/loop6
建议:Hindsight 部署前确保至少 15GB 可用空间。
六、第四个坑:Embedding 配置
6.1 本地模型 vs 外部 API
Hindsight 默认使用本地 embedding 模型(bge-small-en-v1.5),但需要下载约 1-2GB 的模型文件,而且是在HuggingFace上下载的,国内没魔法访问不了,再加硬件配置不高,就直接使用了外部embedding API(向量模型),我这直接使用了 BAAI/bge-m3,而bge-m3中文支持比默认模型好太多。
# 使用外部 OpenAI 兼容的 embedding API
HINDSIGHT_API_EMBEDDINGS_PROVIDER=openai
HINDSIGHT_API_EMBEDDINGS_OPENAI_MODEL='bge-m3'
HINDSIGHT_API_EMBEDDINGS_OPENAI_API_KEY='your-key'
HINDSIGHT_API_EMBEDDINGS_OPENAI_BASE_URL='https://llm.zengwu.com.cn/v1'
6.2 Embedding 维度问题
不同模型维度不同,首次启动需要确认:
bge-m3: 1024 维bge-small-en-v1.5: 384 维
注意:如果切换 embedding 模型,需要清空数据库重新初始化,因为向量维度不兼容。
七、第五个坑:切换外部 PostgreSQL
7.1 为什么需要外部数据库
嵌入式 PostgreSQL(pg0)适合开发测试,但生产环境建议使用:
- 独立的数据库实例
- 更好的性能和可维护性
- 方便备份和监控
7.2 配置外部数据库
docker run -d --name hindsight --restart unless-stopped \
-p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_PROVIDER=openai \
-e HINDSIGHT_API_LLM_API_KEY='your-key' \
-e HINDSIGHT_API_LLM_BASE_URL='https://llm.zengwu.com.cn/v1' \
-e HINDSIGHT_API_LLM_MODEL='glm-5' \
-e HINDSIGHT_API_EMBEDDINGS_PROVIDER=openai \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_MODEL='bge-m3' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_API_KEY='your-key' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_BASE_URL='https://llm.zengwu.com.cn/v1' \
-e HINDSIGHT_POSTGRES_URL='postgresql://hindsight:password@192.168.1.119:5432/hindsight' \
ghcr.io/vectorize-io/hindsight:latest
7.3 坑:外部 PostgreSQL 需要 pgvector 扩展
错误现象:
org.postgresql.util.PSQLException: ERROR: could not open extension control file "vector": No such file or directory
原因:外部 PostgreSQL 需要安装 pgvector 扩展。
7.4 安装 pgvector 扩展
如果 PostgreSQL 是 Docker 容器(如 1Panel 管理):
# 进入 PostgreSQL 容器
docker exec -it postgresql bash
# Alpine Linux 使用 apk
apk add pgvector
# 安装可能失败,需要手动编译或使用预编译包
# 推荐直接使用带 pgvector 的 PostgreSQL 镜像
更好的方案:使用官方带 pgvector 的镜像
# 使用 ankane/pgvector 镜像
docker pull ankane/pgvector
# 或者在 docker-compose 中指定
image: pgvector/pgvector:pg16
安装扩展后,在数据库中创建:
CREATE EXTENSION IF NOT EXISTS vector;
7.5 验证 pgvector 安装
# 连接数据库
psql -h 192.168.1.119 -U hindsight -d hindsight
# 检查扩展
SELECT * FROM pg_extension WHERE extname = 'vector';
# 应该看到
oid | extname | extversion
-------+---------+------------
16384 | vector | 0.8.1
八、完整启动命令(最终配置)
docker run -d --name hindsight --restart unless-stopped \
-p 8888:8888 -p 9999:9999 \
-e HINDSIGHT_API_LLM_PROVIDER=openai \
-e HINDSIGHT_API_LLM_API_KEY='your-api-key' \
-e HINDSIGHT_API_LLM_BASE_URL='https://llm.zengwu.com.cn/v1' \
-e HINDSIGHT_API_LLM_MODEL='glm-5' \
-e HINDSIGHT_API_EMBEDDINGS_PROVIDER=openai \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_MODEL='bge-m3' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_API_KEY='your-api-key' \
-e HINDSIGHT_API_EMBEDDINGS_OPENAI_BASE_URL='https://llm.zengwu.com.cn/v1' \
-e HINDSIGHT_POSTGRES_URL='postgresql://hindsight:password@192.168.1.119:5432/hindsight' \
-e HTTP_PROXY='http://192.168.1.104:1081' \
-e HTTPS_PROXY='http://192.168.1.104:1081' \
ghcr.io/vectorize-io/hindsight:latest
九、验证部署
9.1 检查服务状态
# 查看日志
docker logs -f hindsight
# 应该看到类似输出
# Hindsight API started on port 8888
# Hindsight UI started on port 9999
9.2 测试 API
# 创建 Bank(记忆存储库)
curl -X POST http://192.168.1.119:8888/v1/banks \
-H "Content-Type: application/json" \
-d '{"name": "hermes", "bankType": "HYBRID"}'
# 存储记忆
curl -X POST http://192.168.1.119:8888/v1/banks/hermes/retain \
-H "Content-Type: application/json" \
-d '{"content": "用户偏好:简体中文", "context": "用户设置"}'
# 搜索记忆
curl -X POST http://192.168.1.119:8888/v1/banks/hermes/recall \
-H "Content-Type: application/json" \
-d '{"query": "用户偏好", "limit": 5}'
9.3 访问 Web UI
打开浏览器访问 http://your-server:9999,可以:
- 查看 Banks 列表
- 浏览存储的记忆
- 进行语义搜索测试
十、Hermes Agent 集成
使用hermes memory setup 设置,可直接编辑 Hermes 配置文件 ~/.config/hermes/config.yaml:
memory:
provider: hindsight
mode: local_external
api_url: http://192.168.1.119:8888
bank_id: hermes
auto_recall: true
auto_retain: true
memory_mode: hybrid
重启 Hermes 后,Agent 会自动:
- 在对话中提取重要信息存储到 Hindsight
- 根据上下文自动召回相关记忆
十一、踩坑总结
| 问题 | 原因 | 解决方案 |
|---|---|---|
| LLM 连接失败 | 使用了 HTTP 而非 HTTPS | 确保端点使用 HTTPS |
| 数据目录权限错误 | 容器内进程 uid=1000 | chmod 777或chown 1000:1000 |
| 磁盘空间不足 | 镜像+数据约 8GB | 扩展磁盘至 20GB+ |
| Embedding 下载失败 | 无法访问 HuggingFace | 使用外部 embedding API |
| 外部数据库报错 | 缺少 pgvector 扩展 | 安装 pgvector 并 CREATE EXTENSION |
十二、真实使用体验
部署完成后,Hindsight 的记忆能力确实增强了 Agent 的智能程度:
- 自动记忆提取:不需要手动标记,Agent 会自动识别重要信息
- 语义搜索精准:bge-m3 1024维向量中文支持和搜索效果都很好
- Web UI 直观:可以方便地查看和管理记忆,就是没有中文页面
但也有一些需要注意的地方:
- 冷启动较慢:首次启动需要约 30-60 秒初始化
- 资源占用:建议至少 4GB 内存,20GB 磁盘
- 外部数据库必要性:生产环境强烈建议使用外部 PostgreSQL,方便备份和维护


评论区